 Karlo
Karlo
인공지능이 사람의 상상을 찰떡같이 이해하고 그림으로 그려낼 수 있을까?
‘심플하면서 화려하게, 고급스럽지만 무난하게, 어떤 느낌인지 알죠?! 이거 ASAP인데 가능해요?’ 이렇게 디자인을 요청했다면, 디자이너는 소위 멘붕에 빠질겁니다. 독심술이나 관심법이 아니고서야 어떻게 찰떡같이 그릴 수 있을까요? 하지만 이런 답답함을 해소하는데 인공지능이 도움이 될지도 모르겠습니다. 세상에 존재하지 않는 독창적인 그림도 AI라면 그려낼 수 있는데요.
대표적으로 OpenAI에서 2021년 1월에 공개한 DALL-E라는 모델이 이러한 텍스트 기반의 이미지 생성 AI 모델의 성공 가능성을 보여줘 많은 사람들을 깜짝 놀라게 하였습니다. DALL-E는 이름에서부터 특별한 의미를 담고 있는데요. 초현실주의 화가 살바도르 달리(Salvador Dalí에서)와 픽사의 애니메이션 월 이(WALL-E)를 합성해 만든 이름입니다. 화가의 이름을 따온 것은 DALL-E가 텍스트를 이해해 이미지를 만들어내는(Text-to-Image) 생성 모델이기 때문입니다.
DALL-E 공개 이후 중국어 기반의 CogView, 러시아어 기반의 ruDALL-E 와 같은 다양한 언어의 Text-to-Image 생성 모델이 개발되고 있습니다. 카카오브레인에서도 영어 기반의 Text-to-Image 생성 모델을 개발 중에 있는데 먼저 카카오브레인의 모델이 그려낸 작품들을 살펴보겠습니다.




텍스트-이미지로 구성된 이종 데이터(multi-modal)를 어떻게 학습시킬까?
이미지, 텍스트, 비디오, 음성 등 데이터의 종류는 다양하지만, 모델의 용도에 따라 한 종류의 데이터를 쓰는게 일반적입니다. 언어모델에서는 텍스트를, 사물인식 모델에서는 이미지를 쓰죠. 하지만 종류가 다른 1개 이상의 데이터, 즉 멀티모달(multi-modal) 자료를 학습시킬 때도 있습니다. DALL-E와 CLIP이 텍스트와 이미지라는 이종 데이터를 함께 학습시킨 멀티모달 AI의 대표적인 예시입니다.

출처: https://ai.googleblog.com/2018/09/conceptual-captions-new-dataset-and.html
먼저 학습을 위해서는 이미지와 이미지를 설명하고 있는 캡션 데이터가 쌍(Pair)로 필요합니다. Text-to-Image 생성 모델을 최소 기능으로 학습시키기 위해서는 적어도 수천만 이상의 텍스트-이미지 쌍이 필요합니다. OpenAI의 DALL-E는 2억 5천만 쌍을 학습에 이용했고 해당 데이터는 Google Conceptual Captions, YFCC100M, 위키피디아에서 추출하였습니다. 데이터셋이 준비됐다면 이제 학습을 시켜야 하는데요. Autoregressive Text-to-Image 생성 모델을 학습하기 위해서는 다음의 2단계 과정이 필요합니다.
Stage 1. VQ-VAE로 시퀀스 길이 줄이기
준비된 텍스트와 이미지의 쌍을 디코더에 학습시키면 되지만 여기서 한 가지 문제가 있습니다. 256×256 해상도의 이미지는 픽셀 레벨에서 무려 65,536 길이를 갖는 시퀀스(sequence)로 표현해야 되는데 이걸 디코더에 넣기엔 컴퓨팅 자원을 과도하게 요구하기 때문에 학습이 매우 어렵습니다. 이를 해결하고자 대부분의 모델이 VQ-VAE(Vector Quantized Variational Autoencoder)라는 방법론을 변형 혹은 발전시켜 디코더가 학습 가능할 정도로 시퀀스 길이를 줄입니다. DALL-E에서는 256×256 해상도의 이미지를 32×32의 해상도를 갖는 discrete 시퀀스로 변형하여 시퀀스 길이를 1024로 대폭 줄였습니다.
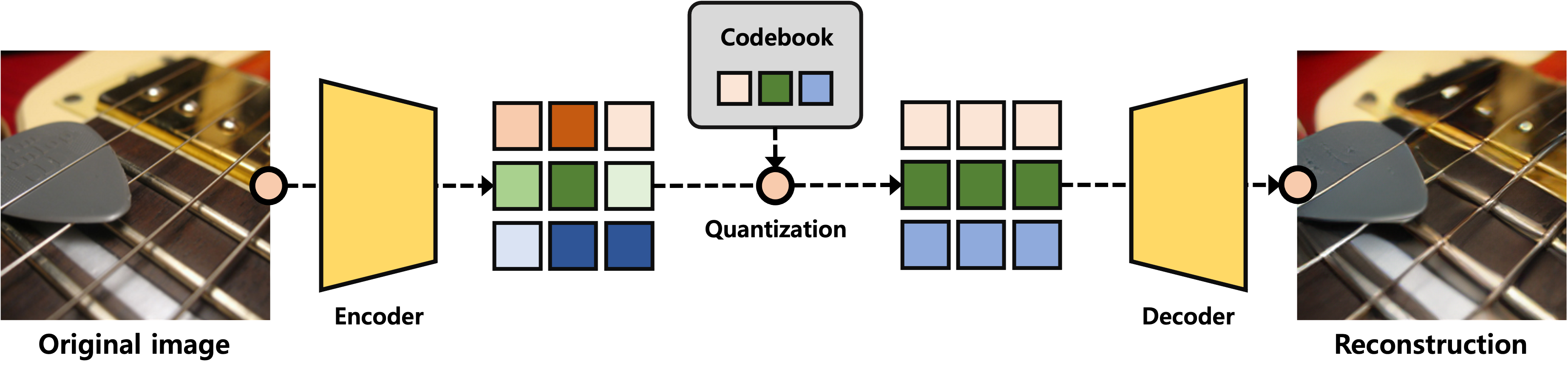
물론 VQ-VAE를 통해 재구축하는 과정에서는 정보 손실이 발생하게 되는데요. 위의 그림을 보면 원본(왼쪽)과 비교해서 재구축된 이미지(오른쪽)는 왜곡이 다소 있는 것을 확인할 수 있습니다. 하지만 이미지의 주요 정보는 충분히 복원했고 시퀀스 길이를 대폭 줄일 수 있기 때문에 VQ-VAE는 autoregressive 모델을 학습하기 전단계로 널리 활용되고 있습니다.
Stage 2. 트랜스포머(Transformer)에 텍스트 – 이미지 토큰 학습시키기
DALL-E는 GPT-3와 마찬가지로 트랜스포머로 구현되어 있습니다. Stage 2에서는 텍스트와 이미지 (정확하게는 VQ-VAE로 변형된 시퀀스)를 트랜스포머 디코더에 넣고 학습시킵니다. GPT-3는 1,705억개의 매개변수를 가진 반면, DALL-E는 120억 개의 매개변수를 가지고 있지만 이 또한 결코 적은 숫자도 아닙니다. DALL-E의 의의는 매개변수의 양이 아니라 텍스트와 이미지로 구성된 이종 데이터를 함께 학습시켜 주어진 텍스트에 알맞는 이미지를 생성할 수 있다는 점입니다.
아래 애니메이션은 Stage 2에서 학습이 완료된 생성 모델이 주어진 텍스트 (A painting of a cherry blossom tree)에 적합한 이미지를 생성하는 과정을 표현한 것입니다. 애니메이션의 왼쪽 그림을 보시면 이미지가 좌상단에서 우하단 순서로 생성되는 것을 보실 수 있고 오른쪽 그림은 이미지의 특정 부분을 생성할 때 어떤 토큰을 선택할지에 대한 확률 분포를 나타내는 것입니다.
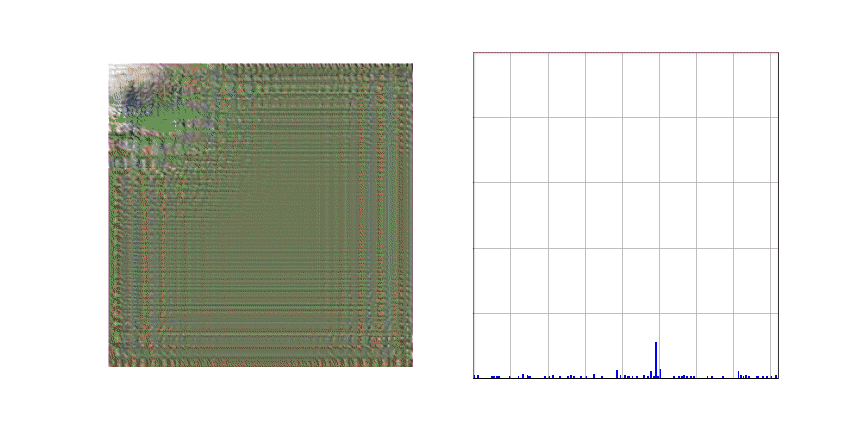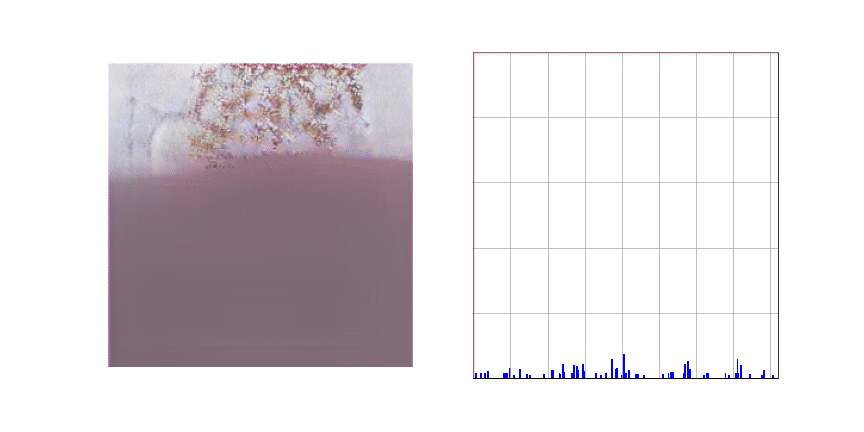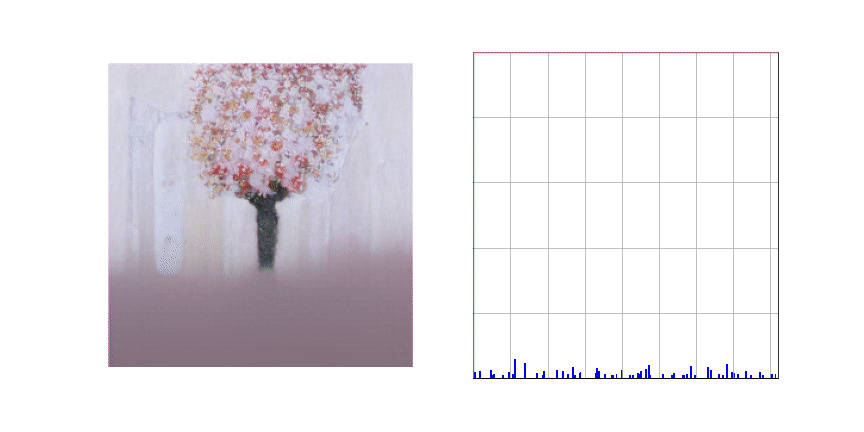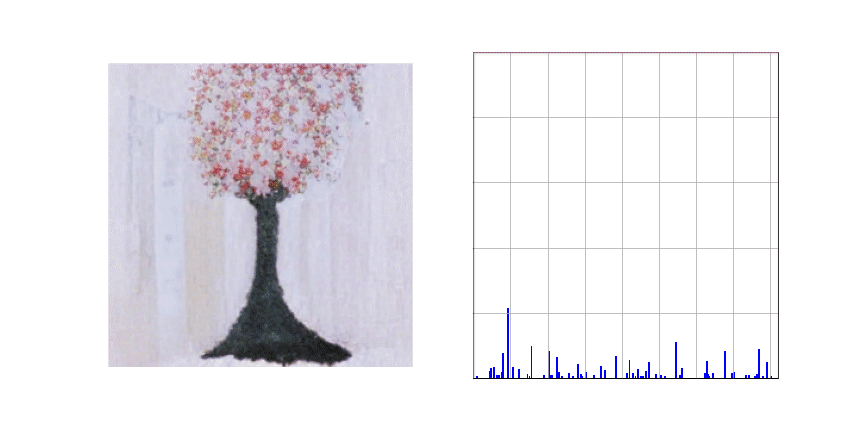
Text-to-Image 생성 모델의 접근성을 높이기 위한 카카오브레인의 노력
DALL-E는 모두가 공감하는 혁명적인 모델이지만, 논문에 소개된 모델이 외부 연구원들이 사용할 수 있는 형태로 공개되지 않았습니다. Autoregressive 모델 기반의 Text-to-Image 생성 과정을 경험하고 다양한 가능성을 열어보고자 하는 연구원분들에게는 너무나도 아쉬운 부분일 겁니다.
카카오브레인은 누구나 Text-to-Image 생성 모델을 경험해볼 수 있도록 minDALL-E를 오픈소스로 공개했습니다. minDALL-E는 쉽게 접근할 수 있도록 작은 사이즈로 만들어진 모델로 1,400만장의 텍스트와 이미지 쌍을 사전 학습시켰습니다. 하이엔드 GPU 1개면 바로 모델을 활용해 볼 수 있는 높은 접근성으로 연구용, 교육용으로 쓰기 용이합니다.
카카오브레인은 minDALL-E 모델 공개와 더불어 현존하는 Text-to-Image 생성 기술의 한계점을 극복하기 위해 자체적으로 다양한 모델을 연구 개발하고 있습니다. 특히, minDALL-E를 비롯한 많은 Text-to-Image 생성 모델들은 상업적으로 활용하기에 생성 시간이 오래 걸리고 품질이 부족한 단점이 존재합니다. 이를 극복하기 위해서 카카오브레인은 상기에 소개드린 stage 1 & 2 모델의 혁신을 지속하고 있고 조만간 다양한 모델들을 오픈 소스로 공개할 예정입니다.

 Krew
카카오브레인, 이렇게 연구합니다! 🔎
Krew
카카오브레인, 이렇게 연구합니다! 🔎

