 Brain Cloud
Brain Cloud
Q. 무엇을 키워야 Large-Scale AI일까요?
카카오브레인은 ‘데이터’와 ‘모델’, ‘계산자원’의 세 가지 요소에 기반을 둔 라지-스케일로 문제를 해결하고 있습니다. 더 큰 모델을 잘 학습하기 위해서는 더 많은 데이터가 필요하게 되고, 이렇게 큰 모델과 많은 데이터를 학습하기 위해서는 많은 양의 계산자원이 필요하게 됩니다. 이 세 가지를 모두 키워서 잘 다룰 수 있는 환경과 기술력을 확보해 다양한 문제를 해결하고 있습니다.
Q. 그렇다면 얼마나 키워야 Large-Scale AI일까요?
먼저 데이터 기준으로 말하자면 보통 ‘이미지넷’으로 알려진 ILSVRC 학습 데이터셋은 약 120만장의 이미지로 딥러닝 연구 분야에서 상대적으로 큰 데이터셋에 속했었습니다. 하지만 최근에 약 1천만 장 수준으로 기존에 공개된 데이터셋들에 비해 10배 이상 큰 데이터셋들이 공개되고 있습니다.
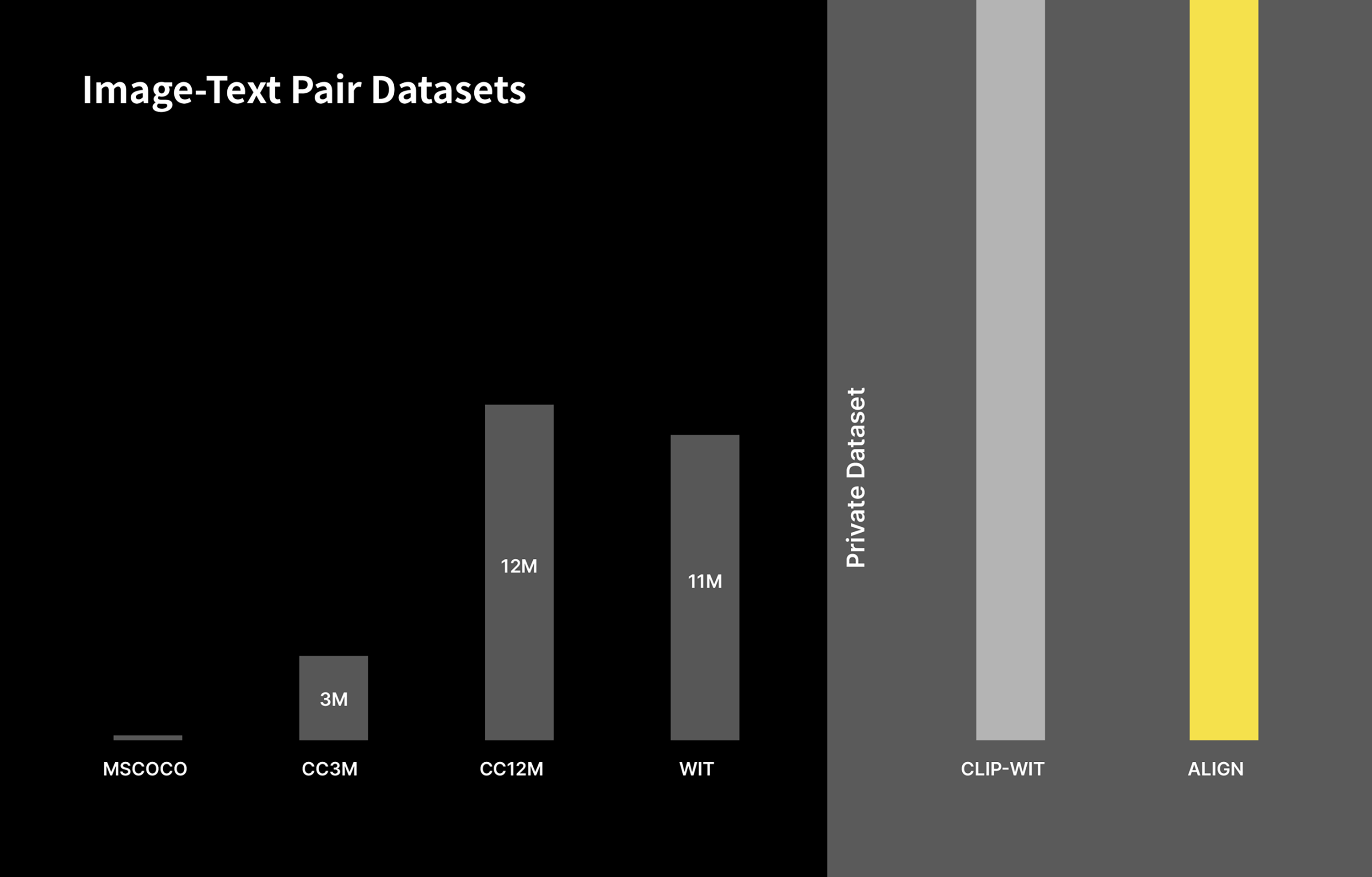
하지만 구글이나 OpenAI와 같이 세계 최고 수준의 AI 모델 개발을 위한 데이터셋은 양은 수억에서 수십억 단위의 내부 데이터셋을 활용해 개발되고 있으며, 공개된 데이터셋으로는 턱없이 부족합니다.
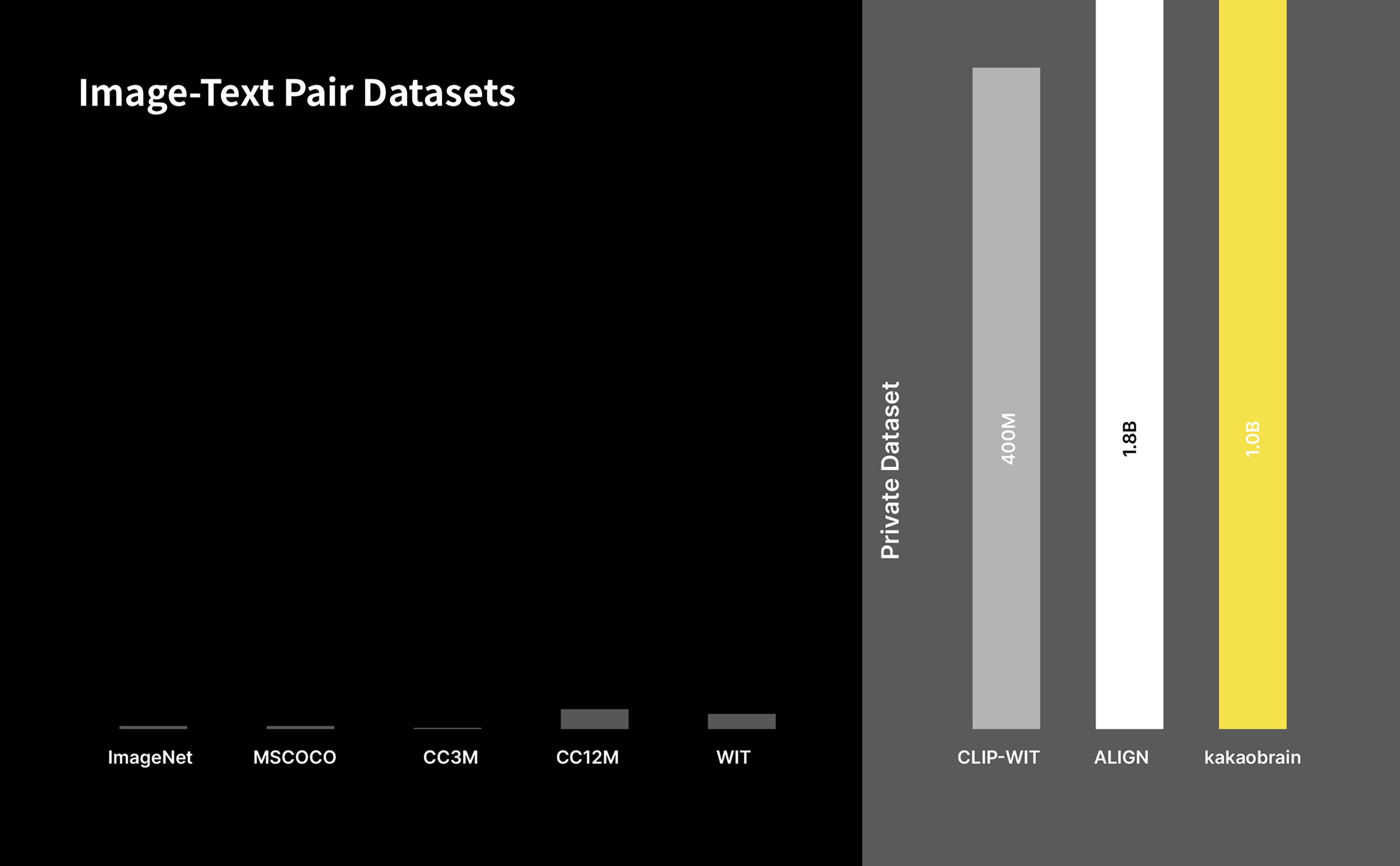
카카오브레인은 웹에서 수집한 수천억 단위의 이미지와 텍스트 쌍을 분석하여 수십 억 단위의 이미지-텍스트 페어 데이터셋을 구축했으며 이를 활용해 세계 최고 수준의 AI 모델을 재현하고 개선하는 한편 데이터셋을 지속적으로 분석 수집해 늘려가고 있으며, 최종적으로 모델 개발에 도움이 되는 고품질 라지-스케일 데이터셋을 만들기 위해 연구 개발하고 있습니다.
이미지 뿐만 아니라 자연어 처리/생성 모델을 위한 자연어 데이터셋과 OpenAI에서 공개한 GPT-3모델을 학습한 300B token 수준의 한글 데이터도 확보하고 있으며, 이를 통해 한국어 GPT 모델을 연구 개발하고 있습니다.
Q. 데이터만 많으면 Large-Scale AI로 문제를 해결할 수 있나요?
데이터셋이 많으면 높은 성능의 모델을 만들 수 있지만 데이터셋의 양에 따른 성능 증가 폭은 점점 줄어들게 됩니다. 즉 데이터만 많이 사용한다고 모델의 성능을 높이는 것은 한계가 있고, 데이터가 충분히 있을 경우 모델의 크기를 키우면 성능을 높일 수 있다고 알려져 있습니다.

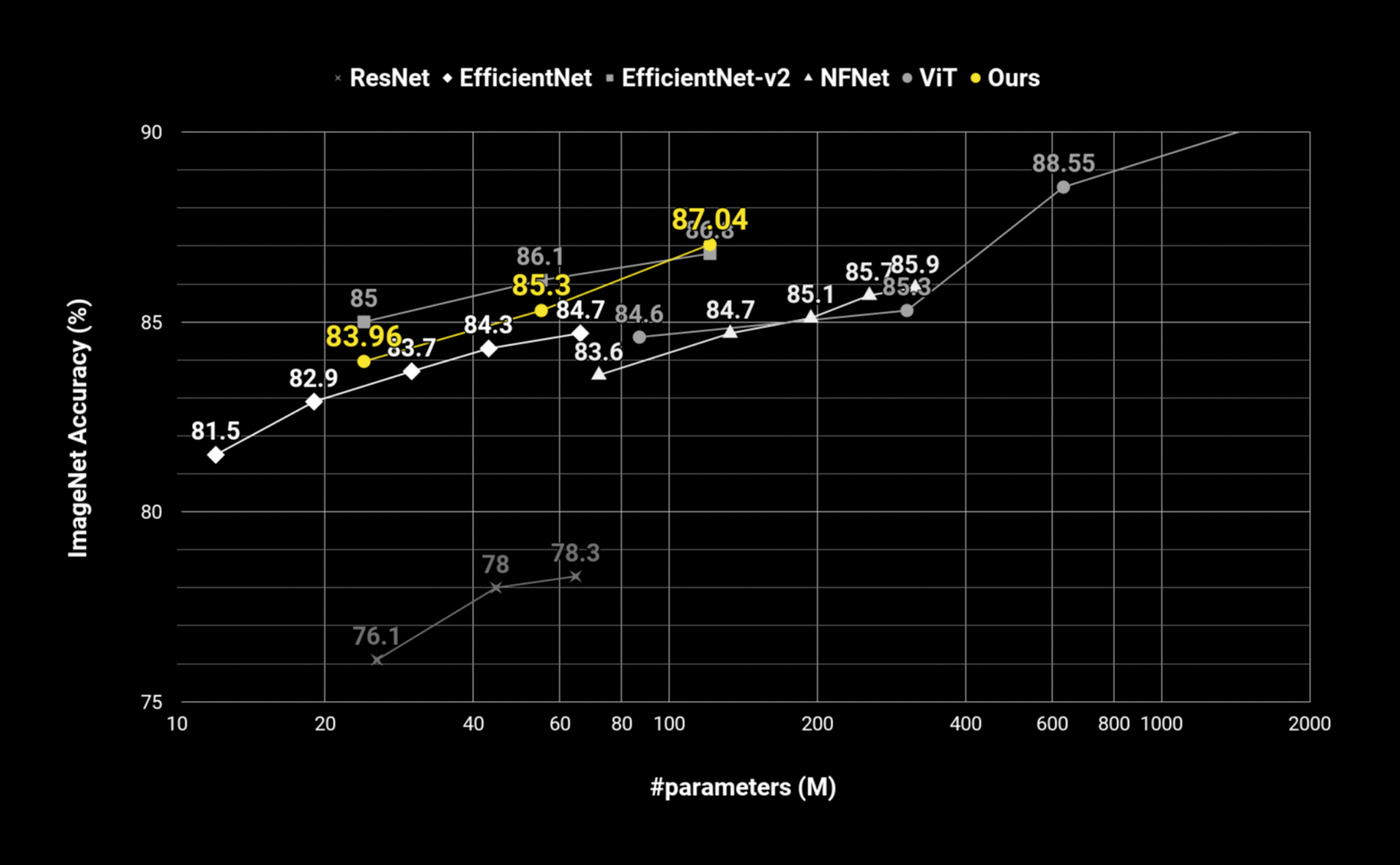
카카오브레인은 Large-Scale AI 데이터셋을 확보했고 그 양이 증가함에 따라 모델 사이즈를 키워서 세계 최고 수준의 AI 모델을 재현 및 연구 개발하고 있습니다.
자연어 생성모델의 경우에도 수십 억에서 수천 억개의 파라미터를 갖는 한국어 GPT 모델을 학습하고 있고, 다른 회사들에서 공개한 모델들 대비 경쟁력있는 성능을 재현하고 있습니다.
Q. 이렇게 많은 데이터와 큰 모델은 어떻게 학습할 수 있나요?
Large-Scale AI의 데이터셋과 모델을 학습하기 위해서는 결국 대용량의 컴퓨팅 파워, 즉 많은 수의 GPU와 같이 계산 자원이 필요로 합니다. 카카오브레인에는 딥러닝 연구 개발에 최적화된 ‘브레인 클라우드’라는 인프라 서비스가 있습니다.
수천 개의 GPU 자원을 손쉽게 할당 및 활용할 수 있으며, Large-Scale AI에서 분산 노드 학습을 위한 최적화 및 다양한 기능을 지원하고 있습니다. 또한 페타바이트 규모의 고용량, 고대역폭의 NAS를 지원하고 연구 개발을 위한 Hyperopt 및 MLOps를 위한 다양한 기능들을 제공하고 있습니다.

카카오브레인은 브레인 클라우드의 GPU 자원을 최대한 활용하고 있으며 필요에 따라 Google TPU Pod을 추가로 활용하고 있습니다. 이를 통해 필요에 따라 순간적으로 수천 개의 계산 노드를 추가적으로 활용하여 Large-Scale AI 연구 개발이 진행되고 있습니다.
Q. 계산 노드를 얼마나 효율적으로 쓰고 있나요?
Large-Scale 데이터로 Large-Scale AI의 모델을 학습하기 위해서는 수백 개애서 수천여 개의 계산 노드를 사용합니다. 일반적으로 기존의 딥러닝 방법론들은 Large-Scale AI 모델을 학습하는데 최적화되어 있지 않습니다. 카카오브레인은 Large-Scale AI 모델 학습을 위한 파이프라인 병렬화인 torchgpipe를 개발해 PyTorch에 기여해 왔습니다.
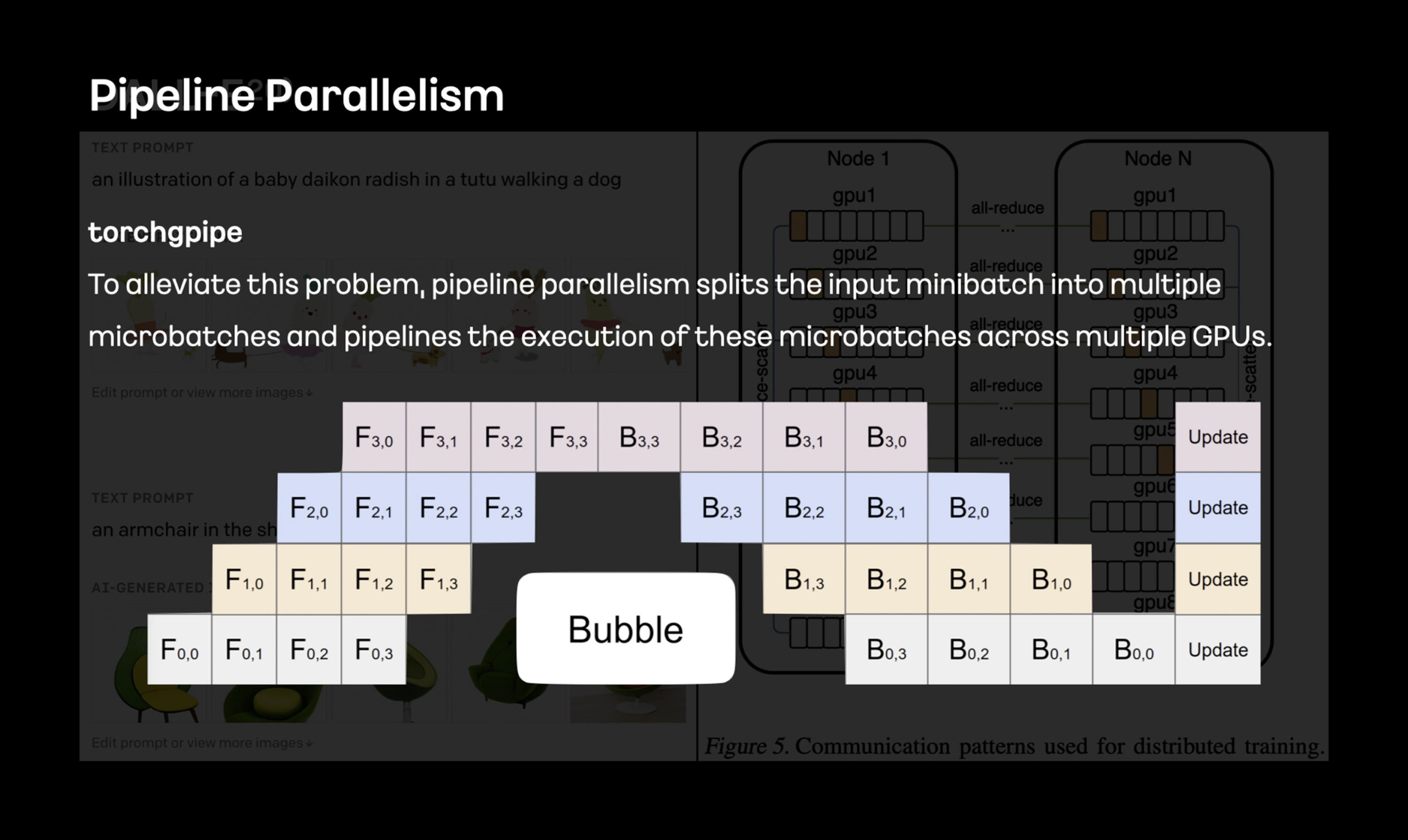
파이프라인 병렬화 뿐만 아니라 메모리 최적화 방법론을 비롯해 데이터 압축을 통해 통신 병목 문제를 해결하고 있으며 이러한 방법론들을 통해 현재 존재하는 하드웨어 제약을 벗어나 더 큰 모델을 학습하는 방법을 연구 개발하고 있습니다.
카카오브레인에서는 Large-Scale AI 학습을 통해 중요하게 생각한 부분은 안정성입니다. 딥러닝 학습은 몇시간 단위를 넘어서 몇일에서 몇 주 혹은 몇 개월이 소모되고, 수백 개의 계산 노드를 활용해 학습하던 중에 단 하나의 장비에 장애나 문제가 생기면 몇 시간 혹은 몇 개월이 걸린 학습 결과물이 사라지거나 사용할 수 없는 경우가 발생합니다.
카카오브레인에서는 Large-Scale AI 학습에 사용되는 인프라와 분산 학습 프레이워크를 다시 고민하고 있습니다.
서로 다른 종류의 계산 노드를 사용하더라도 각 계산 노드에 최적화된 배치 사이즈를 사용해 최대한의 효율성을 확보하고, 네트워크 대역폭에 따라 동적으로 최적의 구성을 찾아 커뮤니케이션하는 방법을 연구 개발하고 있습니다.
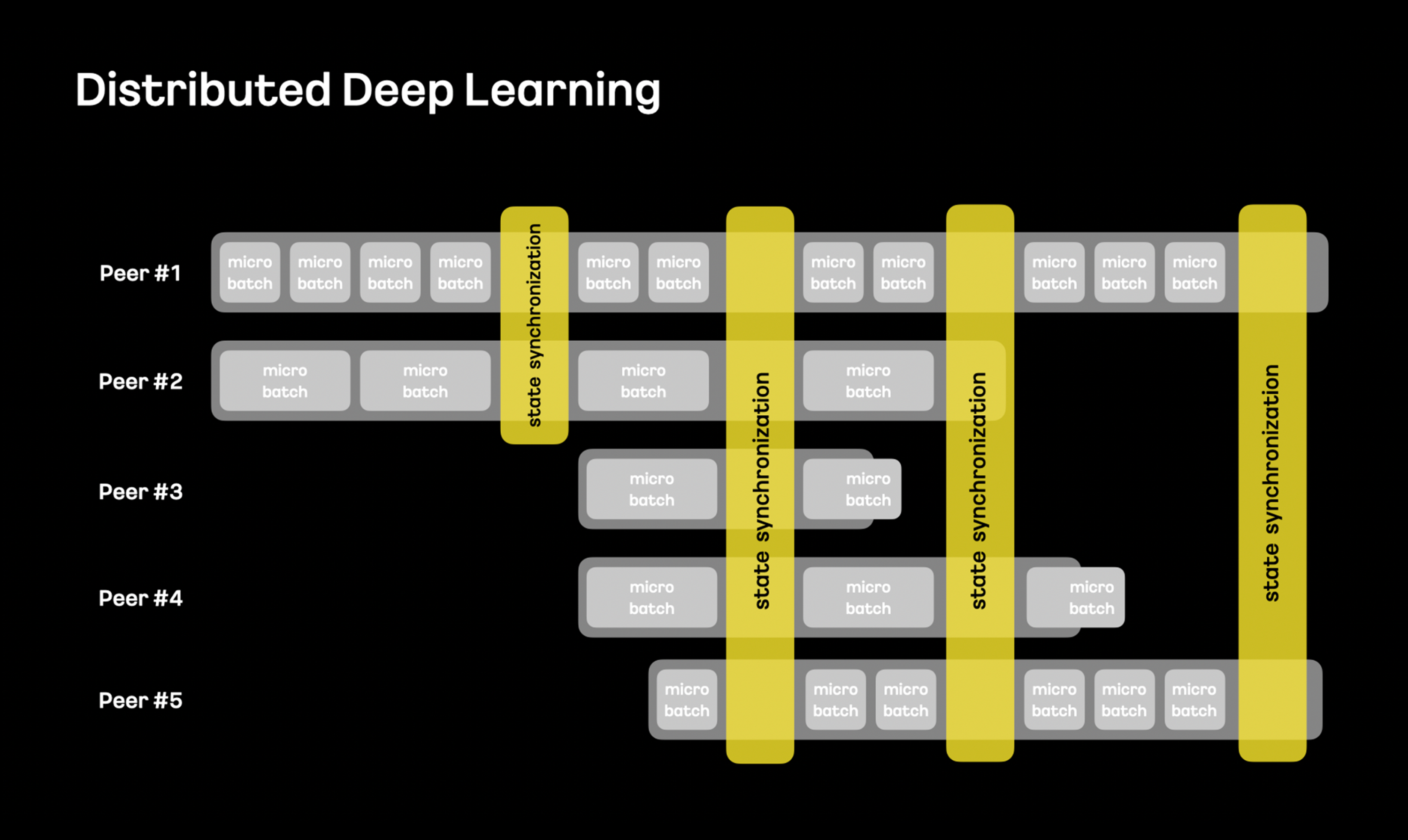
특히나 학습에 참여하는 계산 노드가 동적으로 추가되거나 학습 중에 제거되더라도 학습 알고리즘에 영향을 주지 않는 방법을 연구 개발하고 있으며, 이를 통해 학습 안정성 및 계산 효율을 큰 폭으로 향상시킬 수 있을 것으로 기대하고 있습니다.

 Krew
카카오브레인, 이렇게 연구합니다! 🔎
Krew
카카오브레인, 이렇게 연구합니다! 🔎

 Karlo
카카오브레인, 컴퓨터비전 연구의 최전선 ‘KCCV 2023’에 가다!
Karlo
카카오브레인, 컴퓨터비전 연구의 최전선 ‘KCCV 2023’에 가다!
